Convert ONNX Model to HEF with Docker

HEF (Hailo Executable Format) is a file format used by Hailo devices to run deep learning models efficiently on edge hardware. Hailo provides specialized AI acceleration, enabling optimized inference for neural networks.
In this blog post, we will walk through the process of converting an ONNX model into a HEF model using Docker. This method allows for cross-platform compatibility, meaning you can follow this tutorial on any operating system. In this case, we will demonstrate the process on Windows.
Prerequisites
Before proceeding, ensure you have the following:
ONNX Model: The model must be one of the models included in the Hailo Model Zoo. In this example, we use a YOLOv8n model from Ultralytics trained for detecting vehicles and license plates.
Docker: Install Docker by following the official installation guide.
Calibration Images: These images help the compiler optimize the model for Hailo hardware, and can be the same images used for training the model, as long as they represent the deployment environment.
According to Hailo’s guidelines, the calibration set should typically consist of 32 to 96 images. However, for improved quantization accuracy, using a larger dataset of 500 to 1,000 images is recommended in forums.
1. Download the Hailo AI Software Suite Docker Image
Go to the Software Downloads (Hailo) page and download the Hailo AI Suite - Docker version for Linux:
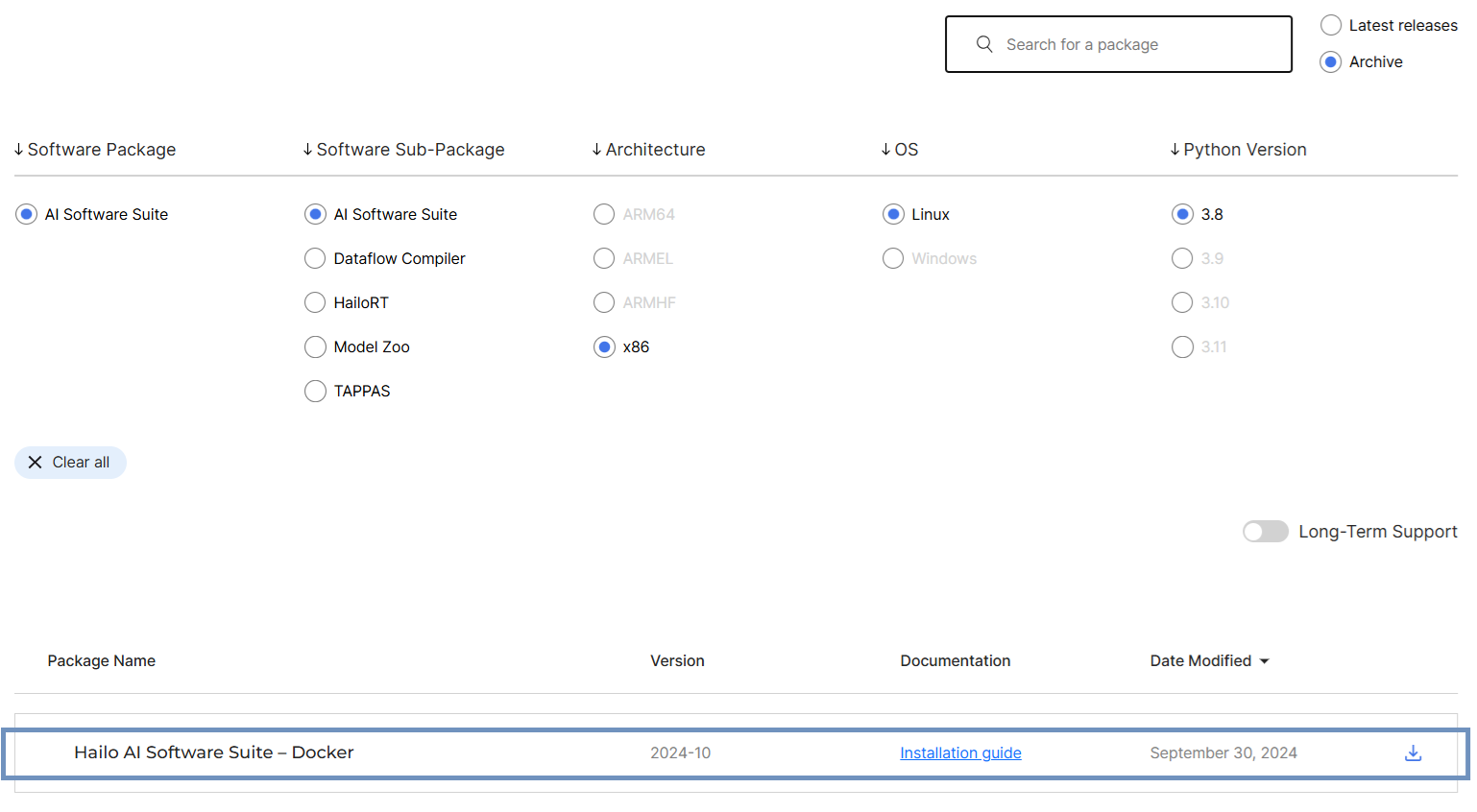
In this case, we downloaded the 2024-10 version of the archive, but any version should work. This download contains a .zip file with the following two files: hailo_ai_sw_suite_2024-10.tar.gz and hailo_ai_sw_suite_docker_run.sh.
2. Load the Docker Image
To load the Docker image, open the command line, go to the unzipped folder, and run the following command:
1
docker load -i hailo_ai_sw_suite_2024-10.tar.gz
Then, verify that the image has been loaded by running:
1
docker images
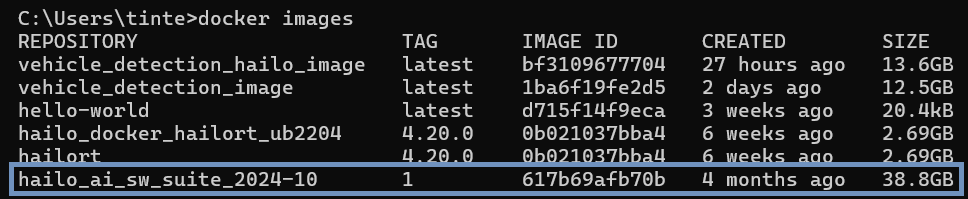
You should see the hailo_ai_sw_suite_<version> image listed:
3. Create a Docker Container
Before creating the container, store the ONNX model weights you want to convert and some sample images in a directory. In this example, we created C:\Users\tinte\Downloads\vehicle_detection containing two subdirectories: models and images:
1
2
3
4
5
6
7
.\vehicle_detection
|-- models
| |-- model.onnx
|-- images
|-- image1.jpg
|-- image2.jpg
|-- ...
Once everything is ready, execute the following command:
1
2
3
4
5
6
7
8
9
docker run -it --name hailo_container \
--privileged \
--network host \
-v /dev:/dev \
-v /lib/firmware:/lib/firmware \
-v /lib/udev/rules.d:/lib/udev/rules.d \
-v /lib/modules:/lib/modules \
-v //c/Users/tinte/Downloads/vehicle_detection:/workspace \
hailo_ai_sw_suite_2024-10:1
The option -v //c/Users/tinte/Downloads/vehicle_detection:/workspace tells Docker to mount the local directory C:\Users\tinte\Downloads\vehicle_detection into the container under the /workspace folder. This means that everything inside vehicle_detection folder (including the models and images subdirectories) will be accessible from within the container at /workspace.
Modify the first part of the path (
//c/Users/tinte/Downloads/vehicle_detection) to match the location of your own files. You can also modify the target directory (\workspace), but it is recommended to maintain consistency with this tutorial.
If the command does not work on Windows (this is my case), try running it as a single line:
1
docker run -it --name hailo_container --privileged --network host -v /dev:/dev -v /lib/firmware:/lib/firmware -v /lib/udev/rules.d:/lib/udev/rules.d -v /lib/modules:/lib/modules -v //c/Users/tinte/Downloads/vehicle_detection:/workspace hailo_ai_sw_suite_2024-10:1
If successful, you will now be inside the container. Navigate to the workspace folder to find your images and models:

If you don’t see your files, check the path (//c/Users/tinte/Downloads/vehicle_detection) specified in the Docker command. Ask ChatGPT how to correctly specify this path for your case.
4. Convert ONNX Model to HEF
Once inside the container, navigate to the models directory and execute the following commands:
A. Parse the ONNX Model
1
hailomz parse --hw-arch hailo8l --ckpt model.onnx yolov8n
Replace model.onnx with the name of your ONNX model file, and yolov8n for the desired HEF model name. This creates a .har file, which is the Hailo model representation.
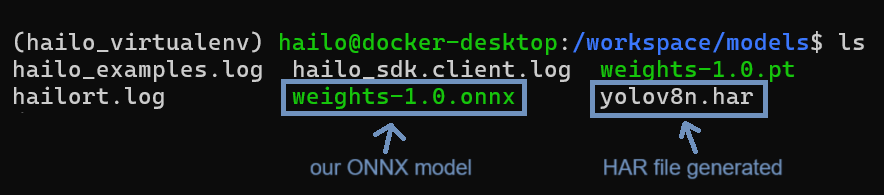
B. Optimize the model
1
hailomz optimize --hw-arch hailo8l --calib-path ../images --resize 640 640 --classes 2 --har yolov8n.har yolov8n --performance
This step fine-tunes the model for the Hailo hardware by applying optimizations based on the calibration dataset:
- Replace
../imageswith the path to your calibration images directory. This isn’t necessary if you followed the same structure as in this tutorial. - Ensure
--resize 640 640matches the resolution used during training. In our case, the YOLOv8 model was trained on640x640images. --classes 2specifies the number of object classes detected by the model—modify it according to your model.--har yolov8n.harshould be replaced with the name of your generated.harfile.- Replace
yolov8nwith the model architecture used in your specific case. - The
--performanceflag prioritizes speed while maintaining accuracy.
When the command completes successfully, you should see an output similar to:
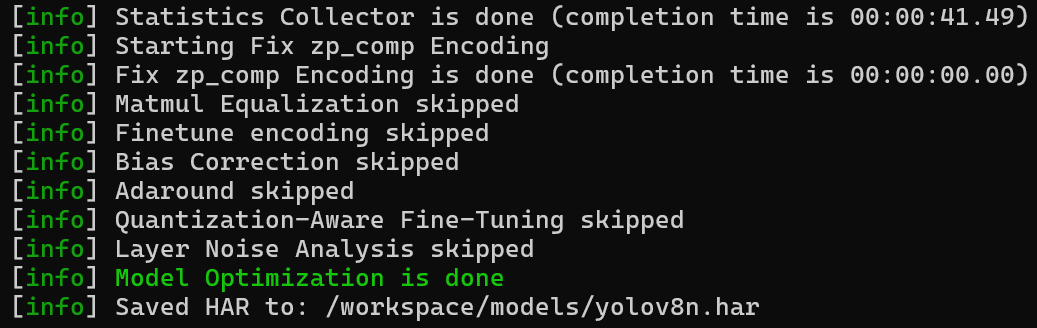
This confirms that the model optimization process is finished and the updated .har file has been saved.
C. Compile the Model into a HEF File
1
hailomz compile yolov8n --hw-arch hailo8l --calib-path ../images --resize 640 640 --classes 2 --har yolov8n.har --performance
This final step converts the optimized model into a .hef file, which is deployable on Hailo hardware.
--hw-arch hailo8lspecifies the target hardware architecture. In this case, the command compiles the model specifically for the Hailo-8L accelerator. If you are using a different Hailo device, ensure this flag matches your hardware.- Replace
../imageswith the path to your calibration images. --har yolov8n.harspecifies the previously generated.harfile. Change the name to match your file.- Replace
yolov8nwith the model architecture used in your specific case. - Modify
--resize 640 640and--classes 2according to your model’s specifications. - The
--performanceflag ensures the model is compiled for optimal inference speed (optional, read below).
Enabling performance optimization (using the
--performanceflag) initiates an exhaustive search for optimal throughput, which can significantly extend compilation time. It’s recommended to first compile without performance mode to ensure successful compilation before enabling it.
By following these steps, you will successfully convert an ONNX model into a HEF file:
