Mezclador de Gatitos - Una Divertida Aplicación de los Autoencoders Variacionales


¿Alguna vez has soñado con poder fusionar dos adorables gatitos en uno solo? ¡Pues ahora puedes hacerlo realidad con el Mezclador de Gatitos! Este proyecto utiliza autoencoders variacionales para crear combinaciones únicas de rostros de gatos, permitiéndote explorar cómo se fusionan distintas características visuales de estos pequeños felinos.
En este post, te contaré brevemente cómo se llevó a cabo el proyecto desde el punto de vista de data science. Empezamos con la introducción de los autoencoders variacionales. Luego, exploramos el dataset de rostros de gatos para entender sus características y cómo esas propiedades impactan en la generación de imágenes. Finalmente, desarrollamos el modelo VAE probando diferentes arquitecturas e hiperparámetros para obtener el mejor desempeño en cuanto a calidad de reconstrucción e interpolación.
¡Explora el Mezclador de Gatitos y crea tus propias combinaciones de gatitos! Visita la aplicación ahora y si te gusta, no olvides darle una estrellita 🌟 en GitHub para apoyarlo.
Introducción a los VAEs
Un Autoencoder Variacional (VAE) es un modelo de red neuronal cuyo objetivo final es aprender una representación comprimida de los datos originales, llamada espacio latente. A diferencia de un autoencoder tradicional, que solo comprime y reconstruye los datos, el VAE aprende a modelar la distribución subyacente de los datos, permitiendo no solo reconstruir imágenes existentes, sino también generar nuevas imágenes realistas a partir de combinaciones o interpolaciones en el espacio latente.
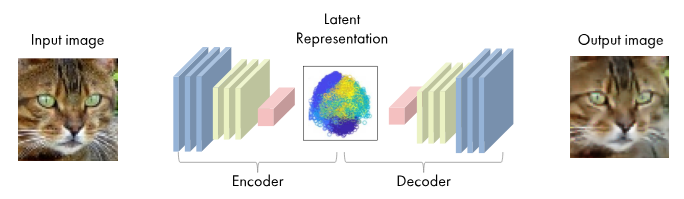
El espacio latente es una representación de menor dimensión donde se capturan las características esenciales de las imágenes, como la forma general del gato, los colores o los patrones de pelaje. Una vez obtenidas las representaciones en el espacio latente de dos imágenes de gatos, es posible realizar interpolaciones entre ellas, generando imágenes intermedias que muestran una transición visual suave y continua entre ambas. Esto permite explorar cómo se fusionarían diferentes características de dos gatos en imágenes generadas artificialmente.

Exploración de Datos
Para abordar este proyecto, utilizamos el dataset Cats Faces 64x64 (for generative models).Este conjunto de datos contiene imágenes de rostros de gatos en resolución \(64 \times 64\) y formato RGB, lo que lo hace ideal para tareas de generación y síntesis de imágenes al reducir la complejidad computacional sin sacrificar detalles relevantes.
El dataset incluye un total de 15,747 imágenes, todas etiquetadas bajo una única clase, gatos. Aunque no cuenta con una documentación detallada, la calidad y uniformidad de las imágenes permiten centrarse exclusivamente en la generación de rostros de gatos, eliminando la variabilidad de múltiples dominios presente en otros datasets más complejos.

Se puede observar que el dataset es altamente adecuado para tareas de generación de imágenes, ya que presenta características consistentes y de calidad. Las imágenes están correctamente recortadas, con un mínimo de fondo, lo que asegura que el rostro del gato ocupa la mayor parte de cada fotografía. Esto reduce la complejidad asociada con variaciones en el entorno o en los elementos de fondo.
Además, se existe una homogeneidad en las poses, ya que la mayoría de los rostros están orientados de frente y mantienen una posición similar en todas las muestras. Esta uniformidad facilita que el modelo generativo enfoque su aprendizaje en las características específicas de los rostros de gatos, incrementando así la probabilidad de obtener resultados coherentes y detallados durante la síntesis de nuevas imágenes.
Desarrollo del Modelo
Se probaron distintas arquitecturas de modelos VAE y, sobre todo, se experimentó con diferentes hiperparámetros. El código implementado para crear VAEs de manera sencilla se encuentra disponible en GitHub, donde se ofrece un paquete que permite construir modelos VAE especificando únicamente la cantidad de canales de cada capa convolucional.
El entrenamiento de los modelos se llevó a cabo utilizando una función de pérdida denominada BetaLoss, que combina dos componentes: la pérdida de reconstrucción y la pérdida latente ponderada por un parámetro \(\beta\). Esta función se define como:
\[\mathcal{L}_{\text{BetaVAE}} = \mathcal{L}_{\text{rec}} + \beta \cdot \mathcal{L}_{\text{latent}}\]El parámetro \(\beta\) controla el equilibrio entre la calidad de reconstrucción y la regularización del espacio latente.
Un valor de \(\beta < 1\) favorece una mejor reconstrucción de las imágenes, mientras que un valor de \(\beta > 1\)
prioriza la regularización del espacio latente mediante una mayor penalización de la divergencia KL.
Modelos Implementados
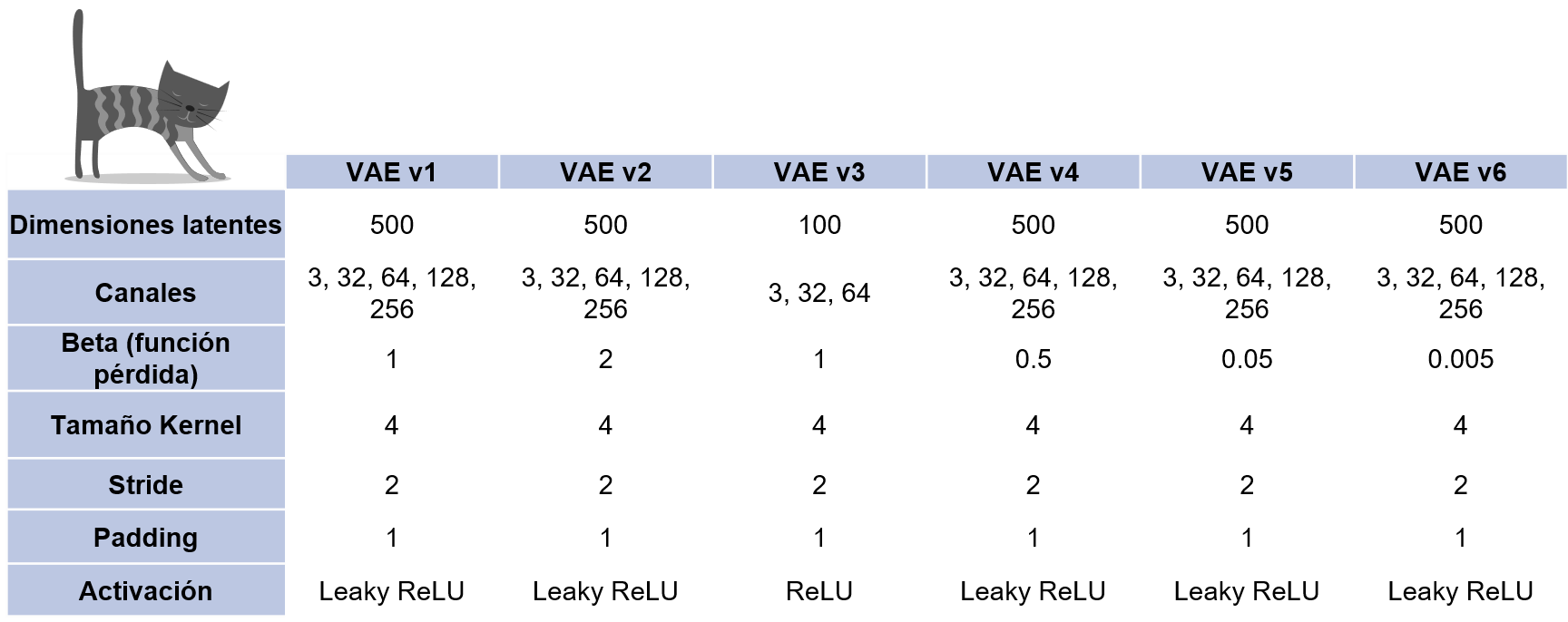
Se probaron 6 versiones de VAE. Los modelos v1, v2, v4, v5 y v6 comparten la misma arquitectura, con la única diferencia en la función de pérdida BetaLoss.
En el modelo v1, se utiliza la función de pérdida estándar de las VAE con un valor de \(\beta = 1\). En el modelo v2, el valor de \(\beta\) se incrementa al doble, es decir, \(\beta = 2\). Por otro lado, en los modelos v4, v5 y v6, el valor de \(\beta\) se reduce progresivamente a \(\beta = 0.5\), \(\beta = 0.05\) y \(\beta = 0.005\) respectivamente. En cuanto al modelo v3, se utilizó una arquitectura más simple, con menos capas y parámetros.
Experimentos
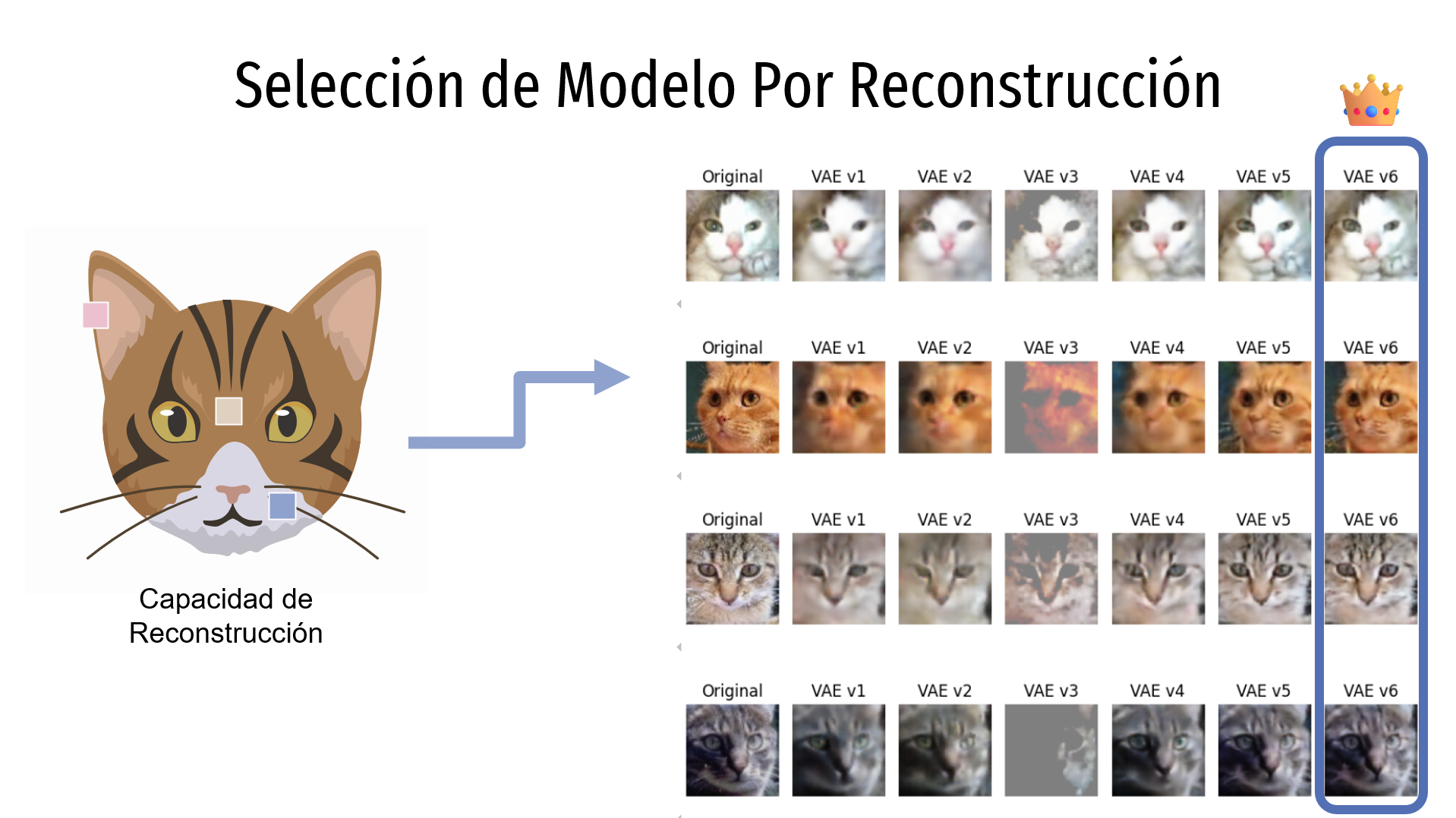
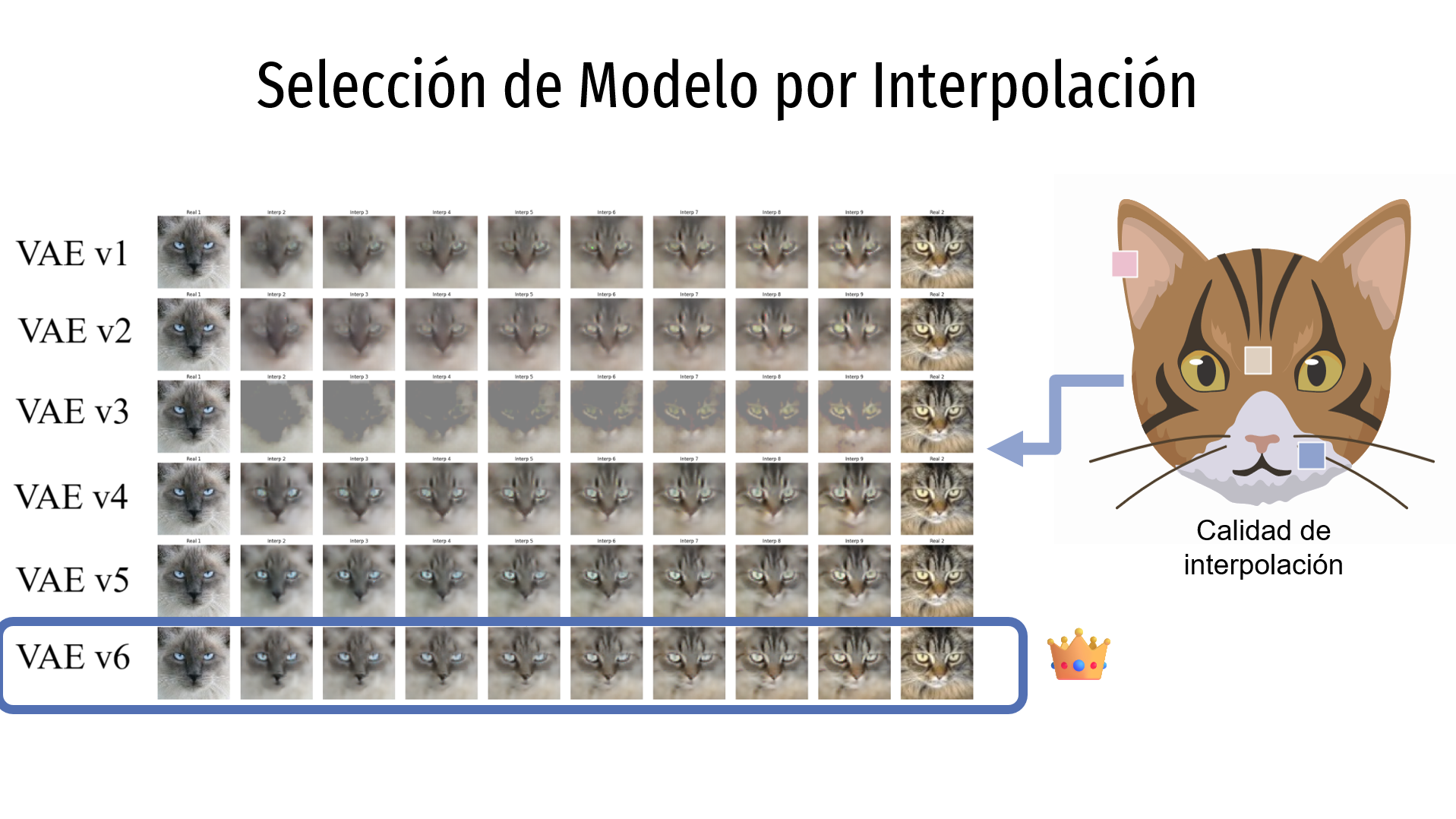
Para seleccionar el mejor modelo, se analizaron algunas muestras de las imágenes generadas y se evaluó la calidad de las reconstrucciones (es decir, qué tan borrosas o nítidas se ven las imágenes reconstruidas) y la calidad de las interpolaciones (es decir, qué tan fluidas y realistas son las transiciones generadas entre dos imágenes distintas).
En cuanto a la reconstrucción, en la imagen se muestran en las columnas los distintos modelos evaluados, mientras que las filas representan diferentes imágenes del dataset. La primera columna corresponde a la imagen original, y cada una de las siguientes columnas representa la reconstrucción generada por cada modelo. Se observa que el modelo VAEv6 es el que produce la mejor reconstrucción.
En cuanto a la interpolación, en la imagen cada fila corresponde a un modelo distinto. La primera y última columna muestran dos imágenes originales del dataset, mientras que las columnas intermedias representan las transiciones generadas entre ambas imágenes. Nuevamente, se observa que el modelo VAEv6 genera las mejores interpolaciones.
Conclusiones obtenidas
A partir de los experimentos realizados, se observó que un aumento en el valor de \(\beta\), que implica una mayor regularización del espacio latente, afecta negativamente la capacidad de reconstrucción de las imágenes. Por esta razón, se descartaron los modelos v1 y v2.
En cambio, al reducir el valor de \(\beta\), la capacidad de reconstrucción mejoró significativamente, sin comprometer de manera importante las interpolaciones. Por este motivo, el modelo v6 (\(\beta = 0.005\)) fue seleccionado como el mejor, ya que ofrece la mejor calidad de reconstrucción sin perder la regularización adecuada del espacio latente.
En cuanto al modelo v3, que presenta una arquitectura más simple y con menos parámetros, esta simplicidad resultó insuficiente para capturar la complejidad de las imágenes de rostros de gatos. Por lo tanto, se consideró inviable para su uso en este contexto.